Are you a Java developer feeling confused about the differences between Apache Spark and Hadoop? Well, you're not alone. Both of these powerful technologies have become synonymous with big data processing and have taken the Java community by storm. However, it's important to understand the differences between the two so that you can choose the right tool for the job. Don't
worry, we've got you covered. In the past, I have shared best Big Data courses and free Apache Spark online courses as well as Big Data and Hadoop interview questions and In this article, we'll take a
light-hearted look at the key differences between Apache Spark and
Hadoop, so that you can finally get some clarity on which technology is
right for you.


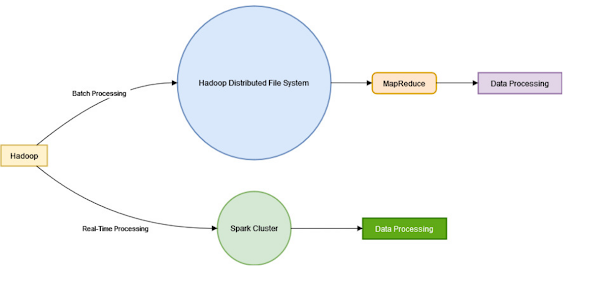
Here are Key differences between Spark and Hadoop
Thanks for reading this article so far. If you like this article then please share them with your friends and colleagues. If you have any questions or feedback then please drop a note.
What is Apache Spark?
Apache
Spark is a lightning-fast, open-source, data processing framework that
was designed to handle big data workloads with ease. It was built with
the goal of providing a more flexible and scalable alternative to Hadoop
MapReduce. Spark is designed to process data in-memory, which makes it
faster and more efficient than Hadoop MapReduce.
Imagine
you're making a huge pot of chili. With Spark, you can chop all the
vegetables and brown the meat in one big pot, rather than doing it one
ingredient at a time, like in Hadoop MapReduce. That's why Spark is
sometimes referred to as the "one-pot chili of big data processing."

What is Hadoop?
Hadoop,
on the other hand, is a collection of open-source software tools that
are used for distributed data processing and storage. Hadoop was
initially developed by the Apache Software Foundation and quickly became
the go-to technology for big data processing.
Hadoop's key component is
the Hadoop Distributed File System (HDFS), which is used to store and
manage large amounts of data.
Think of Hadoop as a big storage
closet where you can keep all your old clothes and memorabilia. You can
store anything and everything in it, and it will keep it safe and
sound. Similarly, Hadoop can store and process any amount of data, no
matter how big or small.

Differences between Apache Spark and Hadoop in Java
- Speed
Spark is faster than Hadoop MapReduce, thanks to its in-memory data processing capabilities.
- Ease
of Use
Spark is designed to be more user-friendly and has a higher-level API compared to Hadoop MapReduce, which makes it easier to develop and maintain.
- Processing Engine
Spark has its own processing engine, while Hadoop uses MapReduce as its processing engine.
- Flexibility
Spark supports multiple programming languages, including Java, Scala, Python, and R, while Hadoop MapReduce is limited to Java.
- Latency
Spark is designed for real-time processing and has a lower latency compared to Hadoop MapReduce.
- Real-time Processing
Spark supports real-time processing, while Hadoop is mainly used for batch processing.

It's
important to note that while Spark and Hadoop were originally designed
to work separately, they can also be used together. Spark can be used as
an in-memory processing engine on top of Hadoop's HDFS, combining the
strengths of both technologies. This hybrid approach can result in a
powerful big data processing solution that can handle both batch and
real-time data processing with ease.
In
addition, both Spark and Hadoop are constantly evolving, with new
features and improvements being added all the time. For example, Spark
has added support for graph processing and has also introduced a new
machine learning library called MLlib, while Hadoop has introduced new
tools for real-time data processing, such as Apache Flink and Apache
Storm.
Another important factor to consider is
the cost. Both Spark and Hadoop are open-source technologies, which
means that they can be used for free. However, the cost of deploying and
maintaining a big data solution can quickly add up, especially when
dealing with large amounts of data. It's important to carefully evaluate
the costs involved before making a decision.
Which one is right for you?
The
choice between Spark and Hadoop ultimately comes down to the specific
needs of your project. If you need to process a large amount of data in
real-time and have a lower latency, then Spark is the way to go.
However, if you need a scalable and reliable storage solution for your
data, then Hadoop is the technology for you.
Use Cases
Both Spark and Hadoop have a wide range of use cases, but here are a few common ones for each technology:
Apache Spark:
- Real-time data processing
- Machine learning and predictive analytics
- Streaming data processing
- Graph processing
Hadoop:
- Distributed data storage
- Batch processing of large data sets
- Data warehousing and business intelligence
- Fraud detection and financial modeling
Conclusion
In
conclusion, both Apache Spark and Hadoop are powerful technologies that
have their own unique strengths and weaknesses. It's important to
understand the differences between the two so that you can choose the
right tool for the job. Spark is designed for real-time data processing
and has a lower latency, while Hadoop is designed for scalable data
storage and batch processing.
In the end, both Spark and Hadoop have their place in the Java big data world and both have helped to advance the field in their own ways. Whether you choose Spark for its speed and ease of use, or Hadoop for its scalability and reliability, you can't go wrong.
Just remember, it's not about choosing the best technology, it's about choosing the right technology for the job.
Other Big Data Articles and Resources you may like:
- Top 5 Courses to learn Apache Kafka
- Top 5 Courses to become a full-stack Java developer
- 10 Advanced Spring Framework courses in Java
- 5 Data Science and Machine Learning Course for Programmers
- Top 5 Pandas courses for Data Analysis
- 5 React Native Courses for JavaScript Developers
- Top 5 NumPy Courses for Beginners
- 5 Free Courses to learn Spring Boot and Spring MVC
- Top 5 Cyber Security Courses for Beginners
- 5 Spring Microservice Courses for Java Developers
- 10 Things Java Developers Should Learn
- 5 Courses that can help you to become Scrum Master
- 10 Free Docker Courses for Java developer to learn DevOps
- 5 Free Jenkins and Maven Courses for Java Developers
P. S. - If you are keen to learn Apache Spark to get into the Big Data
space but looking for free online courses to start with then you can also
check out this
free Apache Spark course
on Udemy to start with. This course is completely free and you just need a
free Udemy account to watch this course.
So, there you
have it folks.
No comments:
Post a Comment
Feel free to comment, ask questions if you have any doubt.