Hello guys, whether you are preparing for Java developer interview or any other
Software Developer Interview, a DevOps Interview or a IT support interview, you
should prepare for SQL and Database related questions. Along with Data
Structure, Algorithms, System Design, and Computer Fundamentals, SQL and
Database are two of the essential topic for programming or technical Job
interview. In the past, I have shared many questions related to
MSSQL questions,
Oracle Questions,
MySQL questions, and
PostgreSQL questions
and in this article, I am going to share both theory based and query based
Database and SQL Interview questions with to the points answers.
This article mainly contains two types of interview questions, first which is based ANSI SQL and applicable to all major database, and the second database specific questions e.g. some questions are based on Oracle database, some are MySQL specific and many are based upon SQL Server.
Depending upon candidate's experience in the respective database, you can ask database specific questions as well. For example, If a candidate says that he has worked for 4 years in SQL server, you can ask about ISNULL() and COALESCE(), and if he has worked a couple of years in Oracle database, then you can ask about MERGE statement and how to write pagination query in Oracle.
1. Give two differences between primary and unique key constraint?
Primary key constraints create a clustered index and don't allow null, while the unique key creates non-clustered and can be null. Another difference is that one table can have only one primary key while it allows having many unique keys. This is one of the easiest questions you can get on any SQL interview, so don't fluff it, it might be the interviewer's weed out question.
2. How many clustered index a table can have?
Only one and that's why only one primary key per table. You can create a clustered index while creating a table or you can add it later.
3. How many non-clustered indexes per table?
As many you want but must be under the limit your vendor enforce e.g. SQL Server allows around 280 indexes, but beware of consequences of adding many indexes on table, it might be able to help you search faster but it has space overheads as well as makes your insert and update slower due to additional time is taken to update indexes.
4. What is the difference between truncate and delete? (answer)
truncate fast, and should be used to remove all data from a table without removing the metadata e.g. index, while delete removes rows one by one and much slower than truncate. delete also create a log and can blow up log segment if you try to clear a large table using delete clause.
5. What is the difference between primary and candidate key in SQL? (answer)
There can be more than one column which can uniquely identify a row, all of these columns are a candidate to become primary key, but apart from those who become primary key or part of it, rest of them are known as candidate keys.
6. What is the difference between UNION and UNION ALL in SQL? (answer)
The union is a special keyword which is used to combine the result of two SQL query e.g. suppose you have to ask all red and blue color balls then you can write two queries to get different color balls and can combine them using the union. Now both can be used to combine but UNION removes duplicate rows while UNION ALL keeps it. A row is considered duplicate if all columns have the same values. remember UNION is based upon data so the name of columns can be different.
7. What is the fastest way to empty a table in SQL? (answer)
In my opinion, truncate is the fasted command to empty a table without dropping it. Alternative can be to DROP and recreate the table. Delete can also be used to clear table but it is much slower than truncate, you should only use delete command to remove only selective rows, as truncate doesn't support conditional delete.
8. What is the difference between WHERE and HAVING clause in SQL? (answer)
Though both where and having are used to filter rows there is a subtle difference between them which become obvious during grouping. Conditions on WHERE clause is used to filter rows before grouping while HAVING clause is used to filter rows after grouping. Also, HAVING can only be used along with GROUP BY clause but WHERE can be used with or without GROUP BY.
9. What is referential integrity? (answer)
Referential integrity is a relational database feature which makes integrity in a relation between two tables. For example, If we have two table Parents and Childs, where ParentID is a foreign key in Childs table, referential integrity prevents you from adding rows in child table a with parent which doesn't exist in Parents table. It can also be used to remove all children if the parent is removed from the primary table.
10. What is normalization? (answer)
11. If I have a column that will only have values between 1 and 250 what data type should I use
12. How do you enforce that only values between 1 and 10 are allowed in a column
13. How do you represent one to one relationship?
( implemented as a single table and rarely as two tables with primary and foreign key relationships)
14. How do you represent one to many relationships?
(splitting the data into two tables with primary key and foreign key relationships)
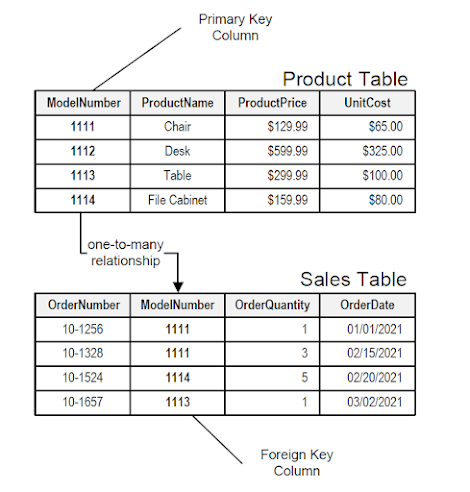
15. How do you represent many to many relationships? (answer)
(implemented using a junction table with the keys from both the tables forming the composite primary key of the junction table
16. How do you count unique rows in an SQL table? (answer)
(by using count() and distinct)
17. What is the inner join, when should you use it? (answer)
18. What is outer join, when should you use it?
19. What is NULL in SQL? How do you test for NULLs? (answer)
(NULL and nothing are different in SQL)
20. What is the result of NULL=NULL and NULL<> NULL? (answer)
(for null checking we use "is null" or "is not null" by the way NULL=NULL IS NULL NULL<> NULL IS NULL)
21. What are 12 rules of Tedd Codd? ( these rules forms basis of RDBMS) (answer)
Seriously I don't remember all those rules so I don't bother asking it but I have seen it asked many times, good luck if you are asked.
22. What is the difference between count(*) and count(employee_name)? (answer)
(former will return a count of all row, later will return only not null row)
23. The difference between view and table? (answer)
(A table is a basic storage for your data in the database. A view is a stored query that appears to be a table. For example: Create view ABC as select from all_tables)
24. Where do you want to use a view? (answer)
(to hide a very complex or frequent join. Instead of typing in the join every time you join multiple tables, you could create a view that would store that query for you)
24. What is the ANSI way of writing join? (answer)
25. What is Equijoin? (answer)
equijoin also called an inner join is a join where matching condition between two table is equal "=".
That is where a column (or multiple columns) in two or more tables match. For our example:
27. What is the difference between clustered and non-clustered index?
A clustered index is a special type of index that reorders the way records in the table are physically stored. Therefore a table can have only one clustered index. The leaf nodes of a clustered index contain the data pages
A non-clustered index is a special type of index in which the logical order of the index does not match the physical stored order of the rows on disk. The leaf node of a non-clustered index does not consist of the data pages. Instead, the leaf nodes contain index rows.
28. Benefits and drawbacks of indexing?
29. You have a SQL script and suddenly your script is taking more time to execute than its normal time? what will you do?
30. If you want to delete a large amount of data which command you use truncate or delete?
(truncate because truncate doesn't log while in case of delete log segment can be blown if there are too many rows to delete)
31. What is a correlated subquery, how is it different with the normal subquery?
32. What is the four isolation level?
33. What is the DUAL table in Oracle database?
34. What is bind variables and why they should be used?
35. How does Index work in SQL?
36. Does the order of index matters in a Query?
37. Difference between DROP, TRUNCATE and DELETE in SQL
DROP will remove both schema and index, no trigger will be fired and cannot be rolled back.
TRUNCATE will only remove all data but again no trigger will be fired and can't be rolled back.
DELETE will remove data, a trigger will be fired and can be rolled back.
38. What is database statistics? How does it affect query performance?
Database statistics are data used by indexes to make your query faster. When you run insert and update command, your database statistics getting out-of-sync, making your query slower, even with right index. To keep your database statistics up-to-date, it's necessary to run update statistics command in SQL Server periodically, mostly after inserting or updating a large number of data into tables.
39. Does order of columns matter in a composite index?
Composite indexes (also known as multiple or concatenated indexes) are special types of the index which use more than one column. Yes, the order of columns in concatenated index matter, because it decides whether the index will be used or not in case you only supply one column in WHERE clause.
40. You have a composite index of three columns, and you only provide values of two columns in WHERE clause of a select query? Will Index be used for this operation?
After imposing the force index you can read the explain plan and verify the cost, if an index scan is costlier than the FTS then it's not a good idea to go with index
41. Is there a way we can suggest database use a particular index in SQL Query?
Yes, by using index hint, as shown in the following query will ensure that SQL server will use an index:
42. Write SQL query to find the third highest salary of an employee without using TOP or LIMIT keyword?
43. Write SQL query to print the name of an employee and their manager?
44. Write SQL query to find all employees joined between date1 and date2?
45. How do you write pagination SQL query in Oracle?
46. How would you select all last names that start with S
47. How would you select all rows where the date is 20221127
51. You have one Query which fetches the values from table A and inserts
into B. but if the A has null row than which exception occurs.
This article mainly contains two types of interview questions, first which is based ANSI SQL and applicable to all major database, and the second database specific questions e.g. some questions are based on Oracle database, some are MySQL specific and many are based upon SQL Server.
Depending upon candidate's experience in the respective database, you can ask database specific questions as well. For example, If a candidate says that he has worked for 4 years in SQL server, you can ask about ISNULL() and COALESCE(), and if he has worked a couple of years in Oracle database, then you can ask about MERGE statement and how to write pagination query in Oracle.
21 Basic SQL Interview Questions and Answers
Now, let's start with the basic SQL interview questions which covers essential SQL concepts like joins, aggregation, indexes, primary and foreign keys, SQL commands like SELECT and DELETE and much more.1. Give two differences between primary and unique key constraint?
Primary key constraints create a clustered index and don't allow null, while the unique key creates non-clustered and can be null. Another difference is that one table can have only one primary key while it allows having many unique keys. This is one of the easiest questions you can get on any SQL interview, so don't fluff it, it might be the interviewer's weed out question.
2. How many clustered index a table can have?
Only one and that's why only one primary key per table. You can create a clustered index while creating a table or you can add it later.
3. How many non-clustered indexes per table?
As many you want but must be under the limit your vendor enforce e.g. SQL Server allows around 280 indexes, but beware of consequences of adding many indexes on table, it might be able to help you search faster but it has space overheads as well as makes your insert and update slower due to additional time is taken to update indexes.
4. What is the difference between truncate and delete? (answer)
truncate fast, and should be used to remove all data from a table without removing the metadata e.g. index, while delete removes rows one by one and much slower than truncate. delete also create a log and can blow up log segment if you try to clear a large table using delete clause.
5. What is the difference between primary and candidate key in SQL? (answer)
There can be more than one column which can uniquely identify a row, all of these columns are a candidate to become primary key, but apart from those who become primary key or part of it, rest of them are known as candidate keys.
6. What is the difference between UNION and UNION ALL in SQL? (answer)
The union is a special keyword which is used to combine the result of two SQL query e.g. suppose you have to ask all red and blue color balls then you can write two queries to get different color balls and can combine them using the union. Now both can be used to combine but UNION removes duplicate rows while UNION ALL keeps it. A row is considered duplicate if all columns have the same values. remember UNION is based upon data so the name of columns can be different.
7. What is the fastest way to empty a table in SQL? (answer)
In my opinion, truncate is the fasted command to empty a table without dropping it. Alternative can be to DROP and recreate the table. Delete can also be used to clear table but it is much slower than truncate, you should only use delete command to remove only selective rows, as truncate doesn't support conditional delete.
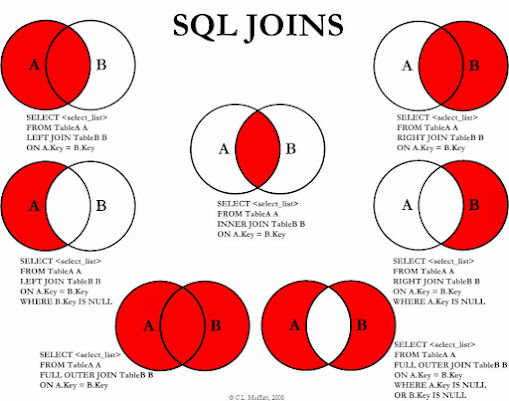
8. What is the difference between INNER and OUTER JOIN in SQL? (answer)
INNER join is used to retrieve matching rows from multiple related tables
while OUTER JOIN is used to retrieve all data from one table and matching
records from another table. There are two types of outer join like LEFT and RIGHT outer join depending upon the all the data you need from that
table.
Here is a nice diagram which illustrate the difference between difference
JOINS in SQL
8. What is the difference between WHERE and HAVING clause in SQL? (answer)
Though both where and having are used to filter rows there is a subtle difference between them which become obvious during grouping. Conditions on WHERE clause is used to filter rows before grouping while HAVING clause is used to filter rows after grouping. Also, HAVING can only be used along with GROUP BY clause but WHERE can be used with or without GROUP BY.
9. What is referential integrity? (answer)
Referential integrity is a relational database feature which makes integrity in a relation between two tables. For example, If we have two table Parents and Childs, where ParentID is a foreign key in Childs table, referential integrity prevents you from adding rows in child table a with parent which doesn't exist in Parents table. It can also be used to remove all children if the parent is removed from the primary table.
10. What is normalization? (answer)
11. If I have a column that will only have values between 1 and 250 what data type should I use
12. How do you enforce that only values between 1 and 10 are allowed in a column
13. How do you represent one to one relationship?
( implemented as a single table and rarely as two tables with primary and foreign key relationships)
14. How do you represent one to many relationships?
(splitting the data into two tables with primary key and foreign key relationships)
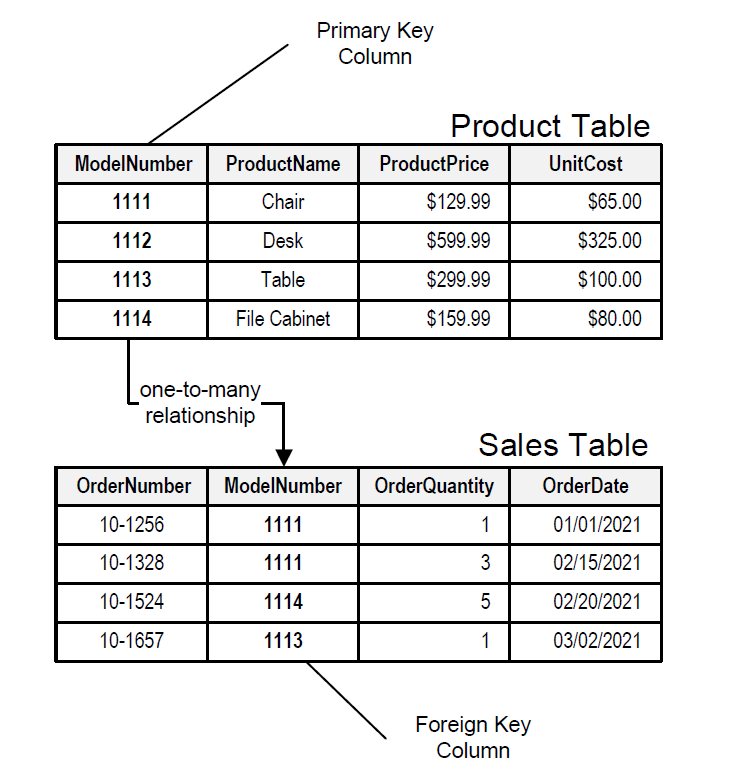
15. How do you represent many to many relationships? (answer)
(implemented using a junction table with the keys from both the tables forming the composite primary key of the junction table
16. How do you count unique rows in an SQL table? (answer)
(by using count() and distinct)
17. What is the inner join, when should you use it? (answer)
18. What is outer join, when should you use it?
19. What is NULL in SQL? How do you test for NULLs? (answer)
(NULL and nothing are different in SQL)
20. What is the result of NULL=NULL and NULL<> NULL? (answer)
(for null checking we use "is null" or "is not null" by the way NULL=NULL IS NULL NULL<> NULL IS NULL)
21. What are 12 rules of Tedd Codd? ( these rules forms basis of RDBMS) (answer)
Seriously I don't remember all those rules so I don't bother asking it but I have seen it asked many times, good luck if you are asked.
22. What is the difference between count(*) and count(employee_name)? (answer)
(former will return a count of all row, later will return only not null row)
23. The difference between view and table? (answer)
(A table is a basic storage for your data in the database. A view is a stored query that appears to be a table. For example: Create view ABC as select from all_tables)
24. Where do you want to use a view? (answer)
(to hide a very complex or frequent join. Instead of typing in the join every time you join multiple tables, you could create a view that would store that query for you)
24. What is the ANSI way of writing join? (answer)
25. What is Equijoin? (answer)
equijoin also called an inner join is a join where matching condition between two table is equal "=".
That is where a column (or multiple columns) in two or more tables match. For our example:
SELECT emp.ename, dept.name FROM emp JOIN dept ON emp.deptno = dept.deptno26. What is the difference between union and join, when to use
what?25 Advanced SQL Interview Questions with Answers
27. What is the difference between clustered and non-clustered index?
A clustered index is a special type of index that reorders the way records in the table are physically stored. Therefore a table can have only one clustered index. The leaf nodes of a clustered index contain the data pages
A non-clustered index is a special type of index in which the logical order of the index does not match the physical stored order of the rows on disk. The leaf node of a non-clustered index does not consist of the data pages. Instead, the leaf nodes contain index rows.
28. Benefits and drawbacks of indexing?
29. You have a SQL script and suddenly your script is taking more time to execute than its normal time? what will you do?
30. If you want to delete a large amount of data which command you use truncate or delete?
(truncate because truncate doesn't log while in case of delete log segment can be blown if there are too many rows to delete)
31. What is a correlated subquery, how is it different with the normal subquery?
32. What is the four isolation level?
33. What is the DUAL table in Oracle database?
34. What is bind variables and why they should be used?
35. How does Index work in SQL?
36. Does the order of index matters in a Query?
37. Difference between DROP, TRUNCATE and DELETE in SQL
DROP will remove both schema and index, no trigger will be fired and cannot be rolled back.
TRUNCATE will only remove all data but again no trigger will be fired and can't be rolled back.
DELETE will remove data, a trigger will be fired and can be rolled back.
Database statistics are data used by indexes to make your query faster. When you run insert and update command, your database statistics getting out-of-sync, making your query slower, even with right index. To keep your database statistics up-to-date, it's necessary to run update statistics command in SQL Server periodically, mostly after inserting or updating a large number of data into tables.
39. Does order of columns matter in a composite index?
Composite indexes (also known as multiple or concatenated indexes) are special types of the index which use more than one column. Yes, the order of columns in concatenated index matter, because it decides whether the index will be used or not in case you only supply one column in WHERE clause.
40. You have a composite index of three columns, and you only provide values of two columns in WHERE clause of a select query? Will Index be used for this operation?
Answer: If the given two columns are secondary index column then the index
will not invoke
but if the given 2 columns contain a primary index( the first col while creating index) then the index will invoke. In your case, the composite index would not work because of the column not included in the where clause.
Still you want to use an index you give an index hint like below:
but if the given 2 columns contain a primary index( the first col while creating index) then the index will invoke. In your case, the composite index would not work because of the column not included in the where clause.
Still you want to use an index you give an index hint like below:
select /*+ INDEX(TABLE_NAME IDX_NAME) */ * from table_name;After imposing the force index you can read the explain plan and verify the cost, if an index scan is costlier than the FTS then it's not a good idea to go with index
41. Is there a way we can suggest database use a particular index in SQL Query?
Yes, by using index hint, as shown in the following query will ensure that SQL server will use an index:
select /*+ INDEX(TABLE_NAME IDX_NAME) */ * from table_name;SQL Query Interview Questions
No SQL interview is complete without asking queries. Most of the time it's the SELECT query which you need to write, but be prepared with INSERT or UPDATE queries as well. In this section, we will look at some of the frequently asked SQL queries from programming interviews.42. Write SQL query to find the third highest salary of an employee without using TOP or LIMIT keyword?
43. Write SQL query to print the name of an employee and their manager?
44. Write SQL query to find all employees joined between date1 and date2?
45. How do you write pagination SQL query in Oracle?
46. How would you select all last names that start with S
47. How would you select all rows where the date is 20221127
SQL Performance Interview Questions
48. If your SQL query takes more time to fetch the record than what should
we do to solve it?
hint: like DB tuning or indexing kind
49. Between Select Count() /Count(1) — Which one is faster in SQL?
Later is faster in PL/SQL but both are almost equivalent in T-SQL. PL/SQL that using count(1) to find the row count was much more high-performing than using count(), as count() fetches all the rows into memory before getting the exact count. I want to know whether this holds true for T-SQL as well, or are the two just the same?
50. If in EMP table I have null EMP_Name, so when we do Order by EMP_Name, then which values come first
The one with NULL will come first
the default ordering is ascending and NULL comes first.
49. Between Select Count() /Count(1) — Which one is faster in SQL?
Later is faster in PL/SQL but both are almost equivalent in T-SQL. PL/SQL that using count(1) to find the row count was much more high-performing than using count(), as count() fetches all the rows into memory before getting the exact count. I want to know whether this holds true for T-SQL as well, or are the two just the same?
50. If in EMP table I have null EMP_Name, so when we do Order by EMP_Name, then which values come first
The one with NULL will come first
mysql> select emp_name, dept_id from employee order by dept_id;
+----------+---------+
| emp_name | dept_id |
+----------+---------+
| Ram | NULL |
| Jack | 1 |
| John | 2 |
| Alan | 3 |
+----------+---------+
4 rows in set (0.00 sec)the default ordering is ascending and NULL comes first.
52. What happens if you don't close the cursor?
It depends on whether you declared the cursor locally or globally (and what the default is in your environment - default is global but you can change it).
If the cursor is global, then it can stay "alive" in SQL Server until the last piece of code is touched in the scope in which it was created. For example, if you call a stored procedure that creates a global cursor, then call 20 other stored procedures, the cursor will live on while those other 20 stored procedures are running until the caller goes out of scope.
It depends on whether you declared the cursor locally or globally (and what the default is in your environment - default is global but you can change it).
If the cursor is global, then it can stay "alive" in SQL Server until the last piece of code is touched in the scope in which it was created. For example, if you call a stored procedure that creates a global cursor, then call 20 other stored procedures, the cursor will live on while those other 20 stored procedures are running until the caller goes out of scope.
I believe it will stay alive at the session level, not the connection level,
but haven't tested this thoroughly. If the cursor is declared as local, then
it should only stay in scope for the current object (but again, this is
theoretical, and I haven't done extensive, low-level memory tests to
confirm).
Not closing a cursor will keep locks active that it holds on the rows where it is positioned. Even after closing a reference is kept to the data structures the cursor is using though (so it can be reopened) These structures are Microsoft SQL Server specific (so it is not just memory space or handles or so) and depend on what the cursor is actually doing, but they will typically be temporary tables or query result sets.
Not deallocating AFAIK only has to do with performance. The aforementioned resources will remain allocated and thus have a negative effect on server performance.
Not closing a cursor will keep locks active that it holds on the rows where it is positioned. Even after closing a reference is kept to the data structures the cursor is using though (so it can be reopened) These structures are Microsoft SQL Server specific (so it is not just memory space or handles or so) and depend on what the cursor is actually doing, but they will typically be temporary tables or query result sets.
Not deallocating AFAIK only has to do with performance. The aforementioned resources will remain allocated and thus have a negative effect on server performance.
That's all about 50+ SQL and Database Interview Questions with Answers for Software
Engineers, Programmers, and Database Administrator of 1 to 3 years and up to 5 years
of experienced. I have tried to include questions from different topics to
provide you a better preparation. If you think a topic or question is missed
feel free to suggest in comments and I will include them in this article, The
ultimate goal is to make this article useful for anyone preparing for SQL and
Database interview questions.
Other Interview Question Articles You may like to
explore
- 21 Git Concept Interview Questions with Answers
- 40+ Object-Oriented Programming Questions with Answers
- 20 Software Design and Pattern Questions from Interviews
- 17 Spring AOP Interview Questions with Answers
- 17 Java Debugging Interview Questions with Answers
- 10 Oracle Interview Questions with Answers
- 30 JavaScript Interview Questions with Answers
- 12 SQL Query Interview questions with solutions
- 10 Java Locking and Multithreading questions
- 25 Recursion Interview questions with answers
- 130+ Java Interview Questions with Answers
- 20 Algorithms Interview Questions for Software Developers
- 20+ Spring Boot Interview Questions with Answers
- 20 JUnit Interview Questions with Answers
- 50 SQL and Database Interview Questions for Beginners
- 15 Cyber Security Interview Questions with Answers
- 25+ Spring Security Interview Questions with Answers
- 35 Python Interview Questions for 1 to 2 years experienced
Thanks for reading this article so far. All the best for your Software
Engineering and Development interviews and if you have any questions
which don't know answer or any doubt feel free to ask in
comments.
No comments:
Post a Comment
Feel free to comment, ask questions if you have any doubt.